E.V.A.D.E - An evaluation framework for AI-driven end-to-end pipelines.
1. Introduction
At CASABLANCA hotelsoftware, our vision is to build tools that augment human skills, empowering hotel staff to focus on what matters most: the guest. The hospitality industry operates in a complex, fast-paced environment where reliability is non-negotiable. As AI development shifts from training individual models toward building robust, verifiable systems, our competitive advantage lies in how we evaluate, monitor, and coordinate AI components to ensure they operate reliably and safely.
State-of-the-art voice agents employ speech-to-speech pipelines that can be implemented in one of two ways. One option is a fully end-to-end speech model that generates speech responses from speech inputs. The other option is an integrated pipeline of automatic speech recognition (ASR), a large language model (LLM), and text-to-speech (TTS).
The CASABLANCA Wave voice agent is currently under development. As a virtual receptionist, it acts as a digital colleague, assisting guests with routine booking requests and other operational issues so human receptionists can dedicate more time to personal, meaningful interactions. Driven by strict technical and data security requirements, Wave is built on a three-stage pipeline of open-source AI models and closed source models.
Recent trends in AI engineering show that continuous evaluation and observability are mandatory for production AI. We can only scale safely if we have strong verification, testing, and feedback loops . Wave incorporates a highly versatile, modular architecture and an advanced AI model evaluation tool to serve these pipeline components reliably.
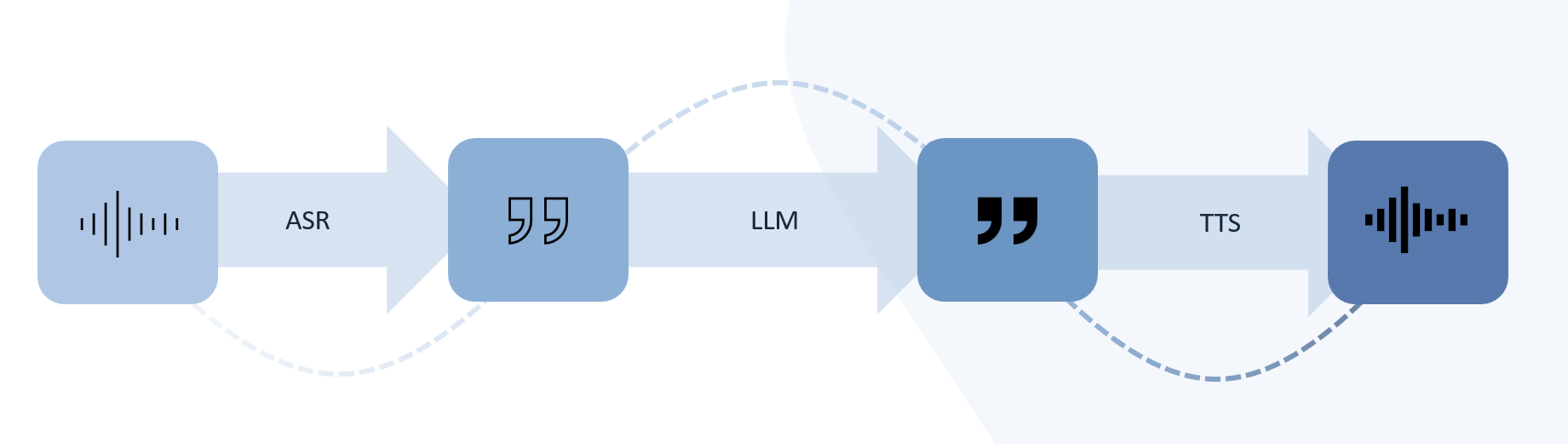
In this post, we introduce E.V.A.D.E., our AI model evaluation framework that uses MLFlow at its core to ensure our autonomous agents perform flawlessly in high-stakes hospitality environments.
2. Requirements
The choice of platform is distinctly driven by Wave's unique technical requirements. The main objective is to develop a plug-and-play speech-to-speech pipeline in which components can be configured individually and agents can be easily customized. This justifies the need for a scalable model registry. Additionally, pipeline components require standalone objective evaluation, which follows different dynamics depending on the stage of the pipeline. Finally, tracking the fine-tuning of AI models and serving the components through self-hosted environments is crucial. We define 6 core feature requirements:
- Model registry (versioning)
- Prompt management (versioning)
- Static model evaluation
- Also usable for model finetuning
- Agent evaluation
- LLM as a judge
- Open source
- Self-Hosted
3. Competitors
Although there is a wide selection of evaluation, model registry, and observability platforms, not all of them meet Wave's requirements. The following table provides an overview of the major competitors.
---

TensorBoard is a popular evaluation framework for AI training and fine-tuning. It is lightweight and easily integrates into any AI pipeline. However, Tensorboard's simplicity is reflected in its lack of features for agent evaluation and model management. This renders it unsuitable for E.V.A.D.E.
---

In contrast, Weights & Biases (W&B) is a much more powerful tool that fulfills nearly all E.V.A.D.E requirements. Although W&B can be deployed on a self-hosted machine, it is ultimately restricted by a paid license, resulting in high costs when used at scale.
---
ClearML offers a very sophisticated open-source platform, which is available for free in a self-hosted environment. It does however lack out of the box features regarding agent evaluation.
---

MLFLow is available for free and can be self-hosted. It covers all desired features including the distinction between agent and model evaluation.
4. E.V.A.D.E
E.V.A.D.E. is an evaluation framework that utilizes many MLFlow features, including the model registry, prompt management, and model and agent evaluation. It is primarily used to swiftly evaluate and compare individual components of a speech-to-speech pipeline. The framework's architecture is divided into three stages that correspond to the three main stages of a standard speech-to-speech pipeline: ASR, LLM, and TTS. The speech stages (ASR and TTS) follow a similar logic and use the same dataset for evaluation. The AI model is evaluated using a German subset of the Common Voice dataset, which includes approximately 220 samples.
For ASR, we calculate RTF, WER, SER and COST. For TTS models, we compute RTF, WER, PESQ, STOI and COST.
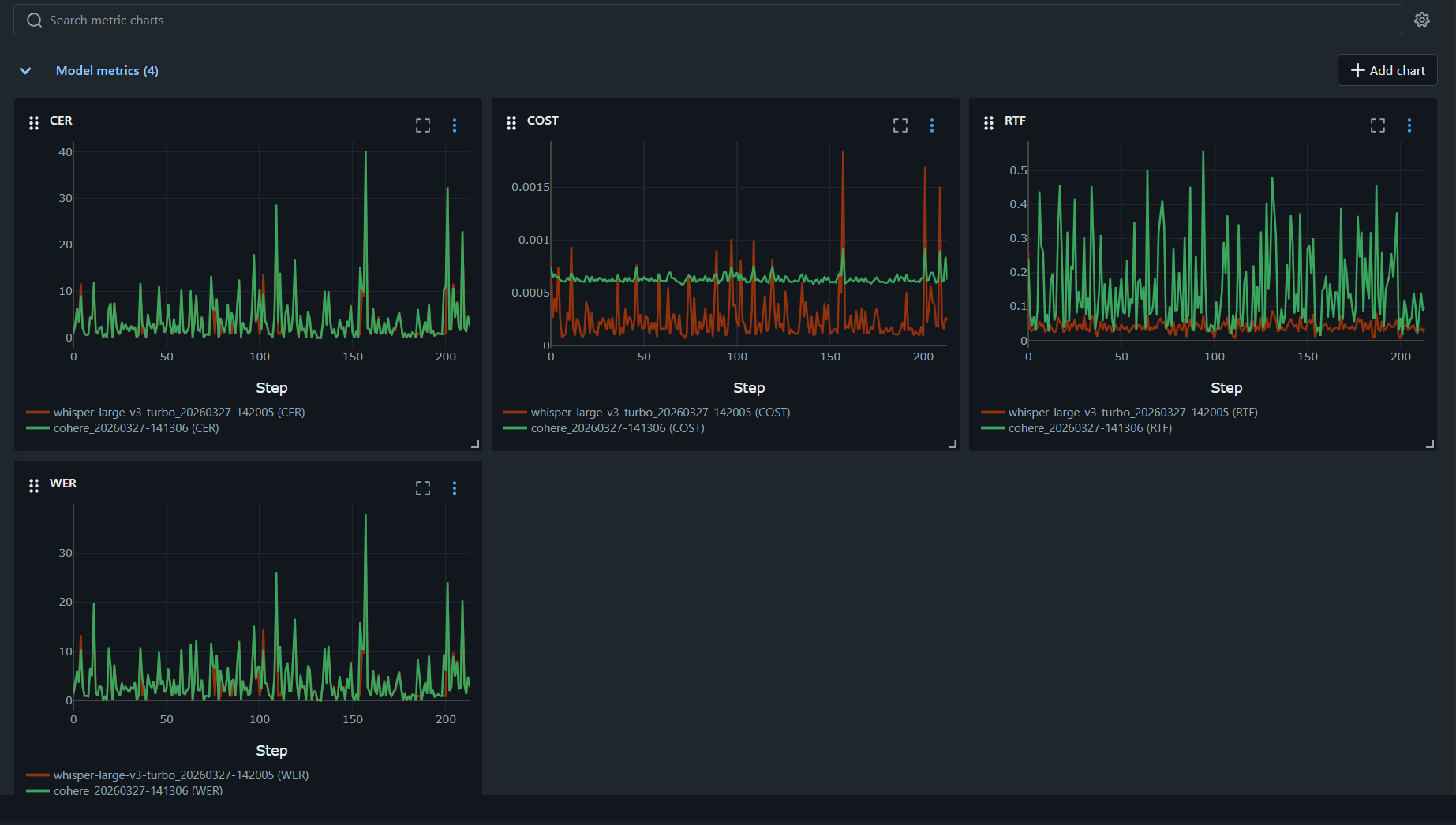
The LLM stage initializes two LLMs to simulate a realistic booking conversation. Both the customer and agent models can be configured individually. Only the agent model is evaluated using Tokens/second, COST, and LLM-as-a-judge. Currently, we utilize MLflow's out-of-the-box LLM-as-a-judge feature to evaluate 13 different aspects of an entire conversation, which includs tool calls, behavior, and conversation flow. This provides us with a robust and immediate baseline for agent performance. However, recent research highlights the method's limitations: in domain-specific tasks, LLM judges only align with human experts 64–68% of the time, often lacking the critical depth required for specialized evaluations [1]. Recognizing these constraints, while we continue to rely on LLM-as-a-judge to establish our baselines, our next step is to investigate additional methods to map, verify, and enforce the operational policies of our agents directly. In addition to model and agent evaluation, MLFlow is used to serve AI models for production use. Models can be deployed as endpoints directly through MLFlow or, if necessary, through a separate service via vLLM.
5. Summary
E.V.A.D.E., powered by MLFlow, is a cornerstone of our AI engineering strategy at CASABLANCA. By building an evaluation framework that is fast, rigorous, and tailored to the unique demands of hospitality, we ensure our autonomous agents operate as reliable digital colleagues. Our choice of MLFlow over its competitors guarantees the features, data sovereignty, and scalability required to safely deploy high-performance speech-to-speech pipelines. Crucially, the framework described in this post allows us to go from discovering a new open-source AI model to a complete, objective evaluation for our specific use cases in under 15 minutes. Ultimately, E.V.A.D.E. empowers us to maintain continuous observability and rapid iteration, seamlessly bringing cutting-edge research into practical applications that truly augment human skills in the hotel industry.
References
[1] Szymanski, A., Ziems, N., Eicher-Miller, H. A., Li, T. J.-J., Jiang, M., & Metoyer, R. A. (2024). *Limitations of the LLM-as-a-Judge Approach for Evaluating LLM Outputs in Expert Knowledge Tasks*. arXiv. https://arxiv.org/abs/2410.20266
