Large, larger, the largest LLM is not always necessary
In recent years, large language models have consistently scaled up, driven by frontier models from OpenAI, Microsoft Azure, Anthropic and Google. As they grow and are trained on more data, these models develop stronger capabilities for handling everyday tasks. For example, on the MMMU-Pro benchmark [1], OpenAI’s ChatGPT 4.1 (released on April 14, 2025) achieved about 51 % accuracy, whereas the later ChatGPT 5.1 (released on November 12, 2025) reached around 76 % accuracy, illustrating substantial performance gains over time [2].
From this perspective, it may appear that newer and larger models consistently deliver higher accuracy; however, this continuous growth is accompanied by increased costs for using frontier models. While such models can accelerate innovation and enable the rapid development of new products, one must ask: is the largest and most advanced model always the best choice for a given use case?
In collaboration with our Austrian partners, c.c.com Moser GmbH and the University of Innsbruck, we continuously exchanged ideas and findings within the GENIUS projects. One of these joint efforts involved evaluating model capabilities in a Retrieval-Augmented Generation (RAG) experiment.
The answer to the question above was clear: Definitely not.
We conducted a joint experiment based on the documentation of the CASABLANCA hotelsoftware. Using this context knowledge, the University of Innsbruck created 250 factoid question–answer pairs (e.g., Question: “Was ist die Statistikliste?” Answer: “ Die Statistikliste ist ein Listengenerator, mit dem Statistiken über die Belegung und den Umsatz von Hotelbetrieben zusammengestellt werden können”).
We used our current internal RAG chat assistant, built on an Azure-based architecture, with GPT-4.1 mini and GPT-4o as the underlying generation models, and a frontier embedding model for semantic retrieval. In addition, a self-hosted prototype system, RAGnaroX (based embedding: multilingual-e5-large, generator: Qwen3-4B) from c.c.com Moser GmbH. , was evaluated for comparison.
The evaluation was conducted using RAGAS, a widely adopted RAG evaluation framework having more than 12k GitHub stars. The results are summarized below.
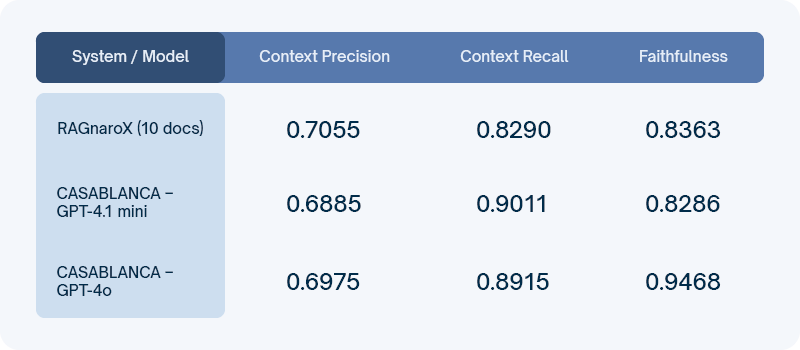
Surprisingly, context precision is nearly identical across all systems, and context recall for the GPT frontier models is very similar, with RAGnaroX close behind. The main difference appears in faithfulness, where GPT-4o clearly leads. However, in this factoid RAG setting based on structured documentation, retrieving the correct context is more important than advanced reasoning. As the answers are directly grounded in the retrieved text, even smaller models can reproduce the required information reliably, making higher faithfulness less critical.

Returning to the cost perspective, the price comparison illustrated in figure shows that GPT-4.1 mini costs only about one quarter of GPT-4o. For our use case, this makes the decision straightforward: we opted to switch to the smaller model.
Not only are smaller language models cheaper to run, they also offer lower latency and greater customizability, which is particularly relevant in RAG systems. When answers are directly grounded in retrieved documents, the additional reasoning capacity of large models provides limited benefit, while faster inference and the ability to fine-tune models to specific document structures or output formats become more important. As highlighted in our research and by research from NVIDIA [4], small language models are therefore a strong fit for domain-specific RAG workloads.
References
1) https://doi.org/10.48550/arXiv.2409.02813
2) https://artificialanalysis.ai/evaluations/mmmu-pro?models=gpt-4-1
3) https://llm-stats.com/models/compare/gpt-4o-2024-08-06-vs-gpt-4.1-mini-2025-04-14
