RESTestBench: Evaluating LLM‑Generated API Tests - Our Latest Paper Accepted at EASE 2026
As the recent shifts in AI Engineering have shown us, writing code is becoming cheaper, but verification is becoming the ultimate bottleneck. As we transition from writing individual lines of code to orchestrating AI agents, our ability to rigidly verify agent behavior against actual human intent is the true scarce resource.
At CASABLANCA hotelsoftware, we strongly believe in bringing practical industry challenges into academic research, and taking frontier research directly into applied software engineering. In our mission to build hospitality tech that augments human skills, we know that AI systems need strong guardrails and verifiable ground truths to enable true scalability.
That is why we are excited to share that our latest research paper, "RESTestBench: A Benchmark for Evaluating the Effectiveness of LLM‑Generated REST API Test Cases from NL Requirements," has been accepted to the EASE 2026 Conference (Evaluation and Assessment in Software Engineering) taking place in Glasgow, Scotland, this June.
Conducted in collaboration with the University of Innsbruck, Technical University of Munich, and Diffblue (within the ITEA4 GENIUS project), this work is a direct product of bridging academia and industry. It builds on our previous exploration with RESTifAI, but addresses the foundational question: If AI agents use natural language requirements to write API tests, how do we know those tests actually verify the intended behavior, rather than simply adapting to a faulty system?
The paper is available as a preprint on arxiv.
From Generating API Tests to Evaluating Them
In our previous work on RESTifAI, and when analyzing other recent tools such as LogiAgent, AutoRestTest, or APITestGenie, we observed two recurring challenges in LLM‑based API testing research.
First, evaluation is often based on insufficient metrics. Many approaches still rely on measures such as:
- code coverage
- number of HTTP 5xx server errors detected
While these metrics are useful for robustness testing, they do not measure whether generated tests actually validate the intended functional behavior of a system.
Second, most existing approaches conflate two distinct problems:
- Requirement generation (deriving requirements or scenarios from artifacts such as OpenAPI specifications)
- Test generation (translating those requirements into executable tests)
When both steps are evaluated together, it becomes difficult to determine whether errors originate from incorrect requirements or from the test generation process itself.
To address these issues, we developed RESTestBench, a benchmark designed to separate requirement specification from test generation and evaluate test effectiveness with respect to explicit requirements.
Why Natural Language Requirements Matter
Another motivation for this work comes from the broader trend toward AI‑supported software engineering. Increasingly, software systems are specified through natural language artifacts, for example:
- user stories
- product requirements
- documentation
- prompt‑based instructions used by AI agents
These natural language descriptions are then used by AI systems to generate or modify software implementations. In such workflows, natural language requirements effectively become the ground truth describing how a system should behave. Consequently, they also serve as a natural test oracle: tests must verify whether the implementation satisfies the behavior described in those requirements. RESTestBench is designed specifically to evaluate whether LLMs can correctly translate such natural language requirements into executable tests.
Introducing RESTestBench
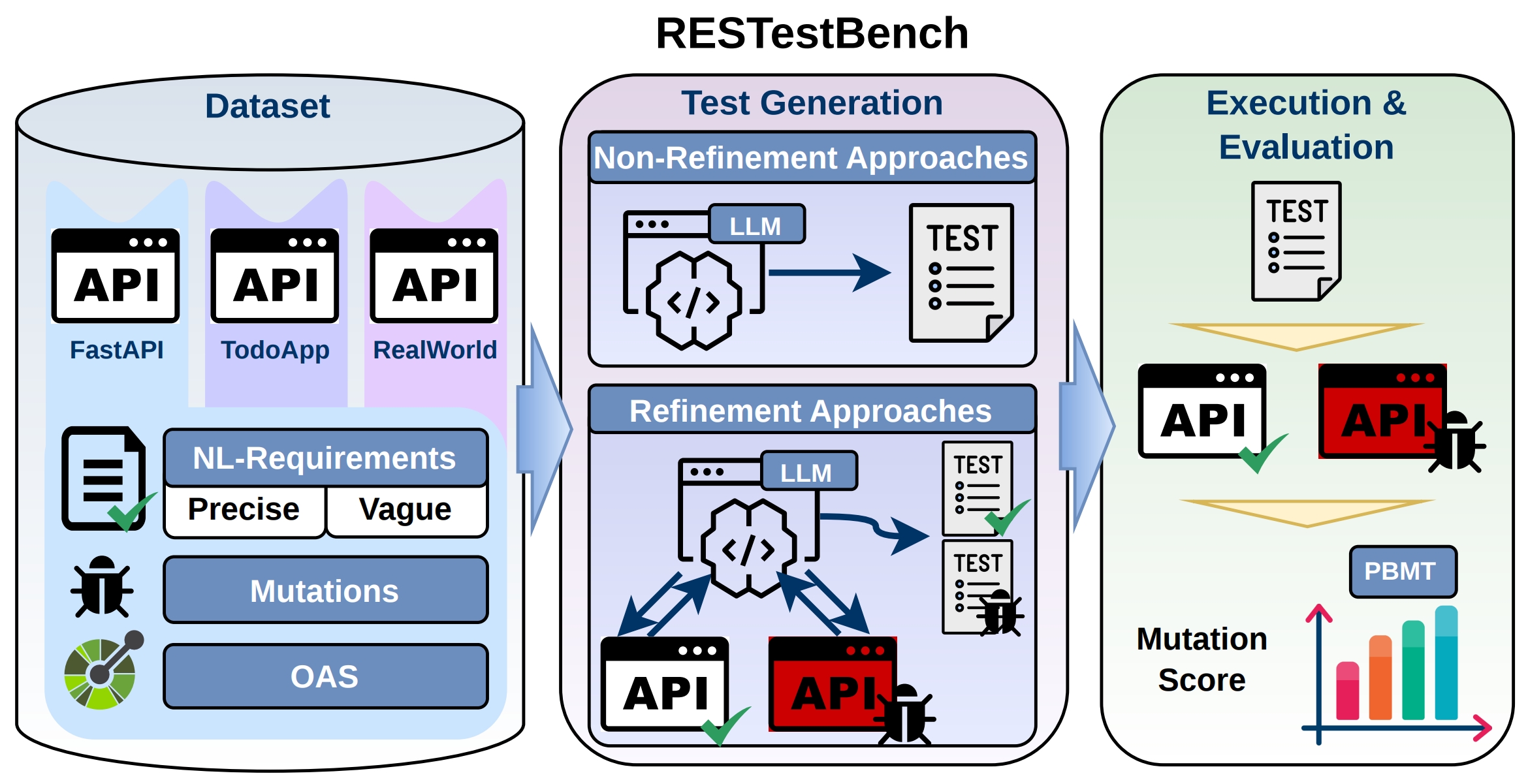
RESTestBench is a benchmark for evaluating requirement‑based REST API test generation. It includes:
- 3 realistic REST services
- 106 manually validated natural language requirements
- Each requirement provided in two variants:
- Precise requirements – detailed and operational
- Vague requirements – high‑level goal descriptions
- 228 manually designed requirement‑based mutations
The benchmark enables controlled evaluation of test generation tools by providing:
- validated requirements
- realistic implementation faults
- reproducible evaluation procedures
This makes it possible to measure whether generated tests actually enforce the intended behavior described in the requirements. Beyond that, the benchmark is specifically designed to assess the effect of interacting with the System Under Test (SUT) during test generation. For tools that use a refinement loop — querying the running service to iteratively improve tests — RESTestBench evaluates generation both against a valid implementation and against a faulty (mutated) implementation. This distinction matters because a requirements-based test should correctly identify faulty behavior rather than adapt to it. When a tool interacts with a faulty SUT, it risks learning the bug: asserting the wrong behavior as correct. The benchmark makes this effect measurable and reproducible. The benchmark is openly available on GitHub.
Property-Based Mutation Testing for Requirements
To evaluate generated tests, RESTestBench applies Property‑Based Mutation Testing (PBMT). Instead of inserting arbitrary code mutations, we introduce mutations that directly violate a specific requirement. A generated test is considered effective if it detects the behavioral change introduced by the mutation. This approach ensures that mutation scores measure something meaningful: whether tests validate the intended requirement, not just incidental implementation details.
Experiments
Using RESTestBench, we conducted experiments with 10 state‑of‑the‑art LLMs from multiple vendors and evaluated two generation strategies:
- Single‑step generation, tests generated directly from the requirement
- Refinement‑based generation, tests iteratively improved through interaction with the running API
The evaluation covered all requirements across three services.
Key Results
Our experiments reveal several important findings.
Requirement Quality Strongly Influences Test Effectiveness
Precise requirements lead to significantly better tests. For detailed requirements, several models achieved mutation scores above 90%, while scores dropped dramatically for vague requirements.
Refinement Loops Help - But Only in Certain Conditions
When requirements are vague, refinement loops that interact with the system can significantly improve test quality. However, when requirements are already precise, the benefits of refinement are much smaller.
Interaction with Faulty Implementations Can Mislead LLMs
When the refinement process observes faulty system behavior, models sometimes adapt their test assertions to match the incorrect behavior, effectively learning the bug instead of detecting it. In these situations, single‑step generation without system interaction can produce more effective tests.
Cost–Effectiveness Varies Strongly Between Models
Smaller models combined with refinement strategies can sometimes achieve similar effectiveness to frontier models at a fraction of the cost. Detailed results and figures can be found in the full paper
The Team Behind the Work
This work is the result of a collaboration between CASABLANCA hotelsoftware GmbH, the University of Innsbruck, the Technical University of Munich (TUM), and Diffblue — carried out within the ITEA4 GENIUS project, which focuses on advancing AI‑supported software engineering methods.
Our collaboration with the University of Innsbruck goes back to the very beginning of the GENIUS project, and it has been a cornerstone of this research. A special thank you to Benedikt Dornauer from the University of Innsbruck for his continued contributions throughout the project. We are also grateful to have TUM involved in this work — Roland Würsching from the Chair of Software and Systems Engineering brought expertise of real caliber to the table, and we would very much welcome the opportunity to collaborate further.
A special thanks goes to Peter Schrammel and the team at Diffblue, whose deep industry expertise in testing enterprise software was invaluable. Their input helped shape the work from the initial idea all the way through to the final paper.
Looking Ahead
Beyond the benchmark itself, our focus is shifting toward a broader and increasingly relevant challenge: how to specify requirements and how to elicit the context needed to define valid, unambiguous requirements.
As software engineering moves in a direction where AI agents act as compilers from natural language to code - translating intent directly into working implementations - the quality and precision of requirements becomes a critical bottleneck. When agents are the intermediaries between human intent and executable software, requirements are no longer just documentation: they become the source language itself.
This shift makes the questions of how to write, structure, and validate requirements more important than ever before - and it is a direction we see as increasingly worth pursuing.
If you are attending EASE 2026 in Glasgow, feel free to reach out - we look forward to discussing the work there.
